Abstract
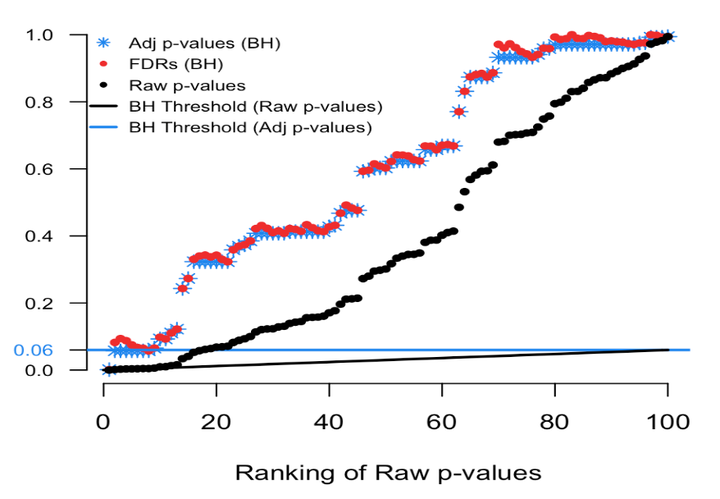
The focus of my oral exam will be on machine learning methods and false discovery rates. These two topics became of interest to me after reading a paper published in April 2018 Nature Methods Journal titled ?Statistics versus machine learning? by Bzdok, Altman, and Brzywinski (Bzdok et al., 2018). The authors advocated for machine learning techniques for large-scale inference, as opposed to traditional statistical methods, which generated a great deal of discussion in the statistics community. I decided to replicate and explore their methods to determine for myself if the comparisons were fair or not. I presented my findings from this project at ENAR 2019. During the coding and computation of these methods I discovered, the popular R function stats::p.adjust did not always return the desired values and did not correctly account for missing values. After researching the available options, I decided to create my own R package for false discovery rate (FDR) estimation. The package is now complete and Professor Jeffrey Blume and I have a corresponding paper that explains our methods and illustrates the package. The paper is in the process of being submitted to The R Journal. My orals will focus on the methodology used in the ENAR presentation and in the R package. Dr. Greevy has agreed that, in combination, these two documents can serve as my oral exam preparation. This document will provide a short introduction to these topics.